Diffusion-Guided Weakly Supervised Semantic Segmentation
Oct 1, 2024·,, ,·
0 min read
,·
0 min read
Sung-Hoon Yoon
Hoyong Kwon
Jaeseok Jeong
Daehee Park
Kuk-Jin Yoon
Abstract
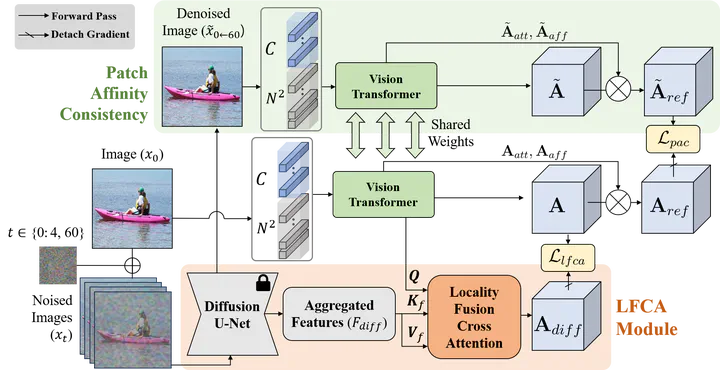
Weakly Supervised Semantic Segmentation (WSSS) with image-level supervision typically uses Class Activation Maps to localize the object based on Convolutional Neural Networks (CNN). With limited receptive fields, CNN-based CAMs often fail to localize the whole object. The emergence of a Vision Transformer (ViT) alleviates the problem with superior performance, but the lack of locality in ViT introduces a new challenge. Inspired by the ability of Denoising Diffusion Probabilistic Models (DDPM) to capture high-level semantic information, we bring diffusion models to WSSS to resolve the problem. Firstly, to fuse and semantically align the information between DDPM and ViT, we design the Locality Fusion Cross Attention (LFCA) module. Using the aggregated features from the denoising process of the pretrained DDPM, LFCA generates CAMs (\ie Diffusion-CAMs) that provide locality information to CAMs from ViT (\ie ViT-CAMs). Secondly, by adding noise to the original image and denoising it with DDPM, we obtain a denoised image that can be leveraged as an augmented sample. To effectively guide ViT in excavating the relation between the patches, we devise the Patch Affinity Consistency (PAC) between the outputs of the original image and the denoised image. Extensive ablation studies support the superiority of the proposed method. Our method achieves new state-of-the-art performance on two widely used datasets in WSSS; PASCAL VOC 2012 and MS-COCO 2014.
Type
Publication
ECCV 2024